for src in $(cat images.list); do image=${src#*/} dest="uhub.service.ucloud.cn/k8s-use/${image}" skopeo --insecure-policy copy --all docker://${src} docker://${dest} done
如果是迁移到其他云服务商的话,还需要注意一个三级路径的问题,多数云服务商的镜像仓库都需要企业版才提供多级路径的功能。所以要么用企业版,要么就需要对镜像重命名。以上面的 for 循环为例,可以把所有的 / 都替换为 -:image=$(echo ${src}| sed 's#^[^/]*/##;s/\//-/g')。
如果删除 pool 报错 Error EPERM: pool deletion is disabled; you must first set the mon_allow_pool_delete config option to true before you can destroy a pool ,则可以添加 mon_allow_pool_delete = true 到 ceph.conf ,然后执行 ceph osd pool delete lotus lotus --yes-i-really-really-mean-it ,或者用下面的方法
# rbd: create error: (33) Numerical argument out of domain # 2020-03-09 22:38:32.177 7fe1a39ecf40 -1 librbd::image::CreateRequest: validate_order: order must be in the range [12, 25]
]]><h2 id="前言"><a href="#前言" class="headerlink" title="前言"></a>前言</h2><p>最近部署的一个项目,启动十几个小时后就报错了,看了下日志输出是 <code>Too many open files</code> 。放到搜索命令行的艺术https://blog.jugg.xyz/2019/05/30/repost/the-art-of-command-line/2019-05-30T18:58:47.000Z2024-06-04T10:08:06.251Z
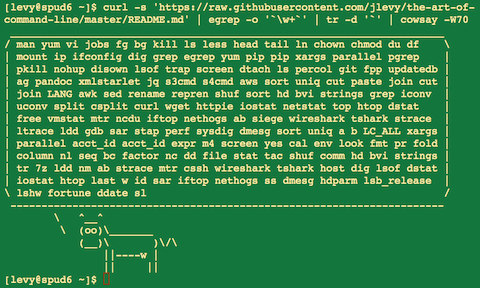
熟练使用命令行是一种常常被忽视,或被认为难以掌握的技能,但实际上,它会提高你作为工程师的灵活性以及生产力。本文是一份我在 Linux 上工作时,发现的一些命令行使用技巧的摘要。有些技巧非常基础,而另一些则相当复杂,甚至晦涩难懂。这篇文章并不长,但当你能够熟练掌握这里列出的所有技巧时,你就学会了很多关于命令行的东西了。
当变量和文件名中包含空格的时候要格外小心。Bash 变量要用引号括起来,比如 "$FOO"。尽量使用 -0 或 -print0 选项以便用 NULL 来分隔文件名,例如 locate -0 pattern | xargs -0 ls -al 或 find / -print0 -type d | xargs -0 ls -al。如果 for 循环中循环访问的文件名含有空字符(空格、tab 等字符),只需用 IFS=$'\n' 把内部字段分隔符设为换行符。
在 Bash 脚本中,使用 set -x 去调试输出(或者使用它的变体 set -v,它会记录原始输入,包括多余的参数和注释)。尽可能地使用严格模式:使用 set -e 令脚本在发生错误时退出而不是继续运行;使用 set -u 来检查是否使用了未赋值的变量;试试 set -o pipefail,它可以监测管道中的错误。当牵扯到很多脚本时,使用 trap 来检测 ERR 和 EXIT。一个好的习惯是在脚本文件开头这样写,这会使它能够检测一些错误,并在错误发生时中断程序并输出信息:
1 2
set -euo pipefail trap"echo 'error: Script failed: see failed command above'" ERR
注意到语言设置(中文或英文等)对许多命令行工具有一些微妙的影响,比如排序的顺序和性能。大多数 Linux 的安装过程会将 LANG 或其他有关的变量设置为符合本地的设置。要意识到当你改变语言设置时,排序的结果可能会改变。明白国际化可能会使 sort 或其他命令运行效率下降许多倍。某些情况下(例如集合运算)你可以放心的使用 export LC_ALL=C 来忽略掉国际化并按照字节来判断顺序。
你可以单独指定某一条命令的环境,只需在调用时把环境变量设定放在命令的前面,例如 TZ=Pacific/Fiji date 可以获取斐济的时间。
注意 OS X 系统是基于 BSD UNIX 的,许多命令(例如 ps,ls,tail,awk,sed)都和 Linux 中有微妙的不同( Linux 很大程度上受到了 System V-style Unix 和 GNU 工具影响)。你可以通过标题为 “BSD General Commands Manual” 的 man 页面发现这些不同。在有些情况下 GNU 版本的命令也可能被安装(例如 gawk 和 gsed 对应 GNU 中的 awk 和 sed )。如果要写跨平台的 Bash 脚本,避免使用这些命令(例如,考虑 Python 或者 perl )或者经过仔细的测试。
用 sw_vers 获取 OS X 的版本信息。
仅限 Windows 系统
以下是仅限于 Windows 系统的技巧。
在 Winodws 下获取 Unix 工具
可以安装 Cygwin 允许你在 Microsoft Windows 中体验 Unix shell 的威力。这样的话,本文中介绍的大多数内容都将适用。
在 Windows 10 上,你可以使用 Bash on Ubuntu on Windows,它提供了一个熟悉的 Bash 环境,包含了不少 Unix 命令行工具。好处是它允许 Linux 上编写的程序在 Windows 上运行,而另一方面,Windows 上编写的程序却无法在 Bash 命令行中运行。
如果你在 Windows 上主要想用 GNU 开发者工具(例如 GCC),可以考虑 MinGW 以及它的 MSYS 包,这个包提供了例如 bash,gawk,make 和 grep 的工具。MSYS 并不包含所有可以与 Cygwin 媲美的特性。当制作 Unix 工具的原生 Windows 端口时 MinGW 将特别地有用。
另一个在 Windows 下实现接近 Unix 环境外观效果的选项是 Cash。注意在此环境下只有很少的 Unix 命令和命令行可用。
实用 Windows 命令行工具
可以使用 wmic 在命令行环境下给大部分 Windows 系统管理任务编写脚本以及执行这些任务。
Windows 实用的原生命令行网络工具包括 ping,ipconfig,tracert,和 netstat。
SELECTCOUNT(DISTINCT staff_id)/COUNT(*) AS staff_id_selectivity, COUNT(DISTINCT customer_id)/COUNT(*) AS customer_id_selectivity, COUNT(*) FROM payment;
Cookie 曾一度用于客户端数据的存储,因为当时并没有其它合适的存储办法而作为唯一的存储手段,但现在随着现代浏览器开始支持各种各样的存储方式,Cookie 渐渐被淘汰。新的浏览器 API 已经允许开发者直接将数据存储到本地,如使用 Web storage API (本地存储和会话存储)或 IndexedDB。
目前以太网使用交换机替代了集线器,交换机是一种链路层设备,它不会发生碰撞,能根据 MAC 地址进行存储转发。
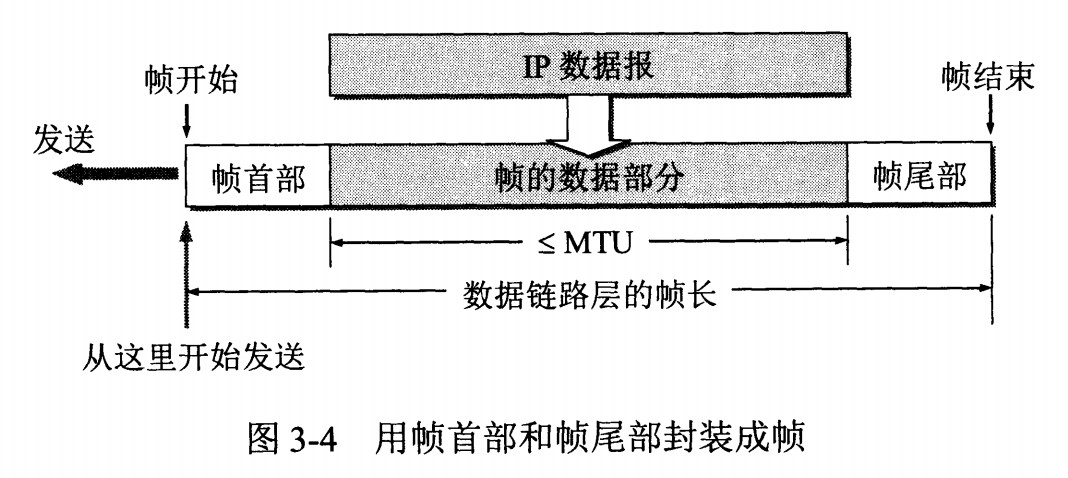
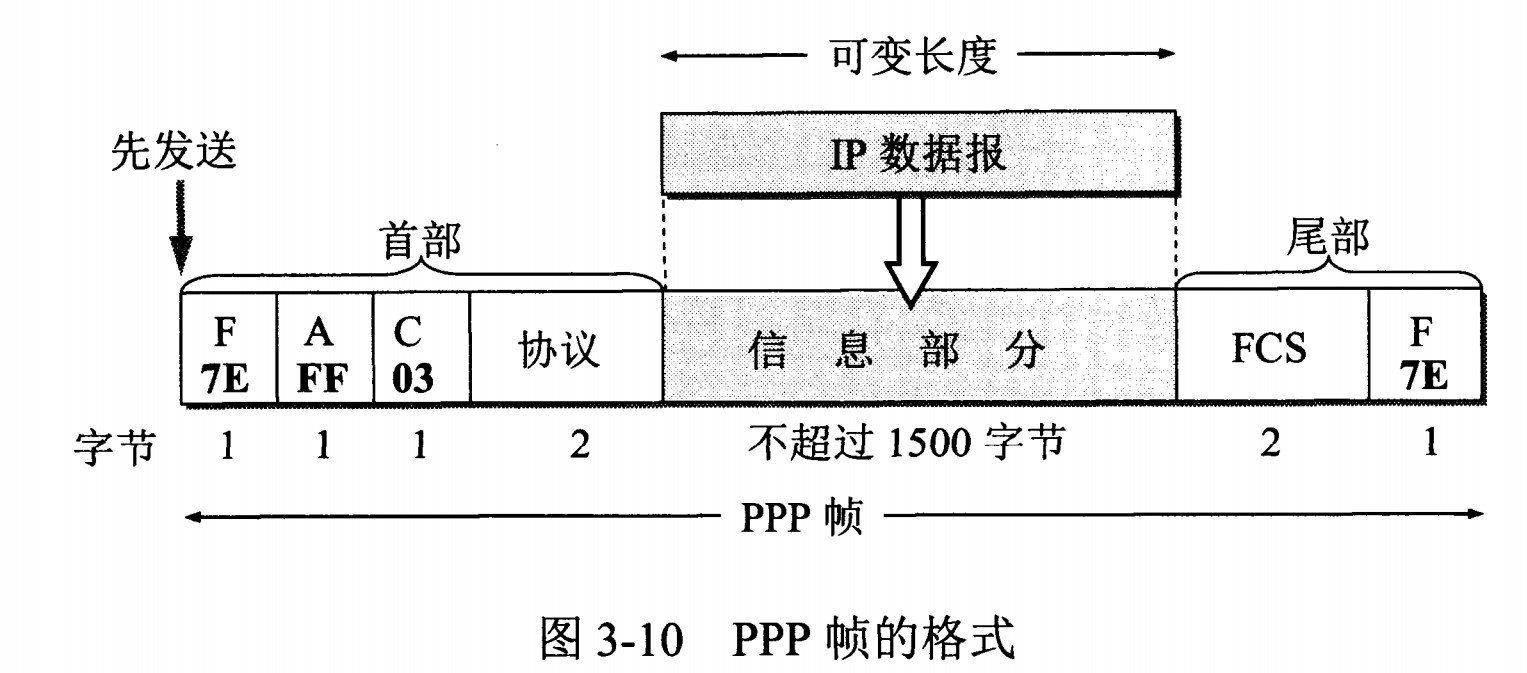
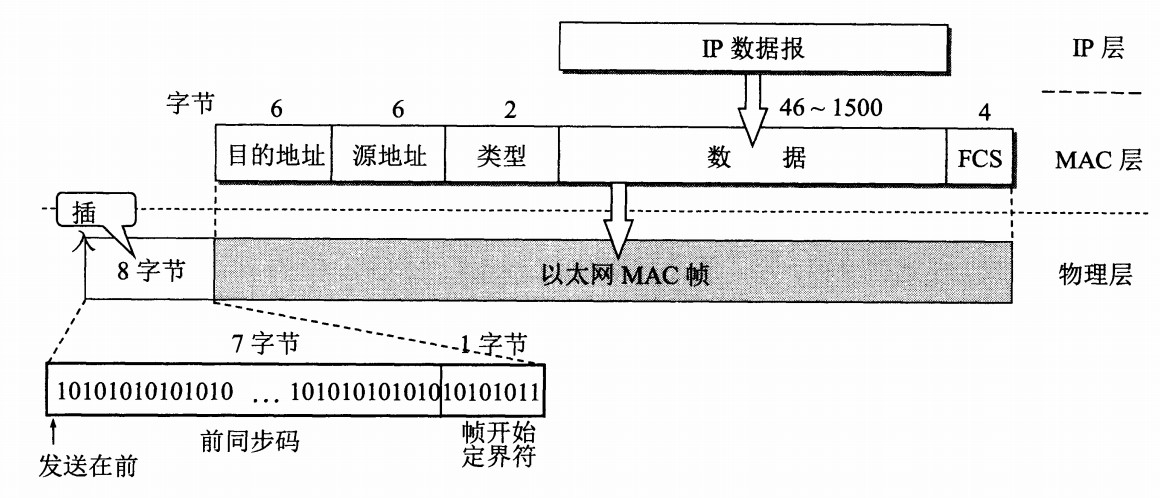
以太网帧格式:
类型 :标记上层使用的协议;
数据 :长度在 46-1500 之间,如果太小则需要填充;
FCS :帧检验序列,使用的是 CRC 检验方法;
前同步码 :只是为了计算 FCS 临时加入的,计算结束之后会丢弃。
交换机*
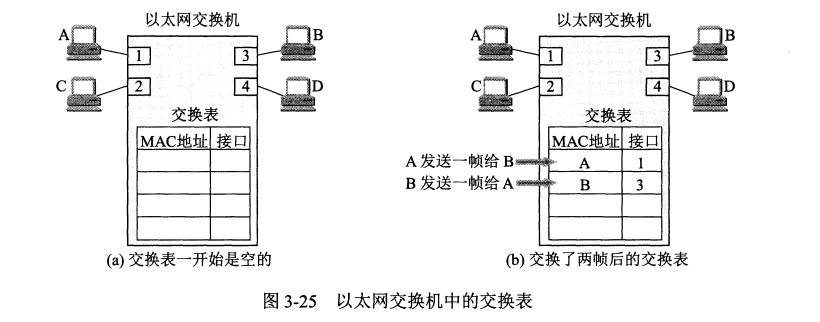
交换机具有自学习能力,学习的是交换表的内容,交换表中存储着 MAC 地址到接口的映射。
正是由于这种自学习能力,因此交换机是一种即插即用设备,不需要网络管理员手动配置交换表内容。
下图中,交换机有 4 个接口,主机 A 向主机 B 发送数据帧时,交换机把主机 A 到接口 1 的映射写入交换表中。为了发送数据帧到 B,先查交换表,此时没有主机 B 的表项,那么主机 A 就发送广播帧,主机 C 和主机 D 会丢弃该帧。主机 B 收下之后,查找交换表得到主机 A 映射的接口为 1,就发送数据帧到接口 1,同时交换机添加主机 B 到接口 3 的映射。
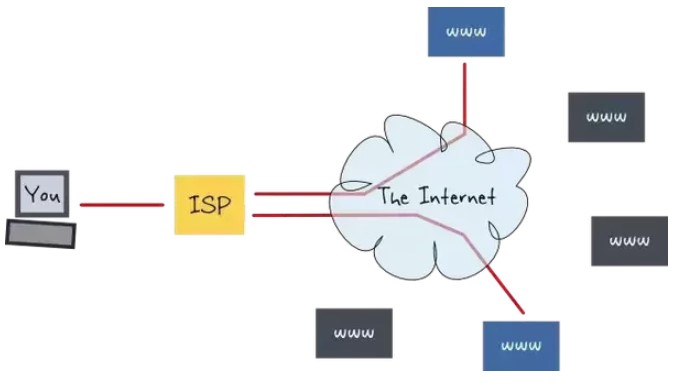
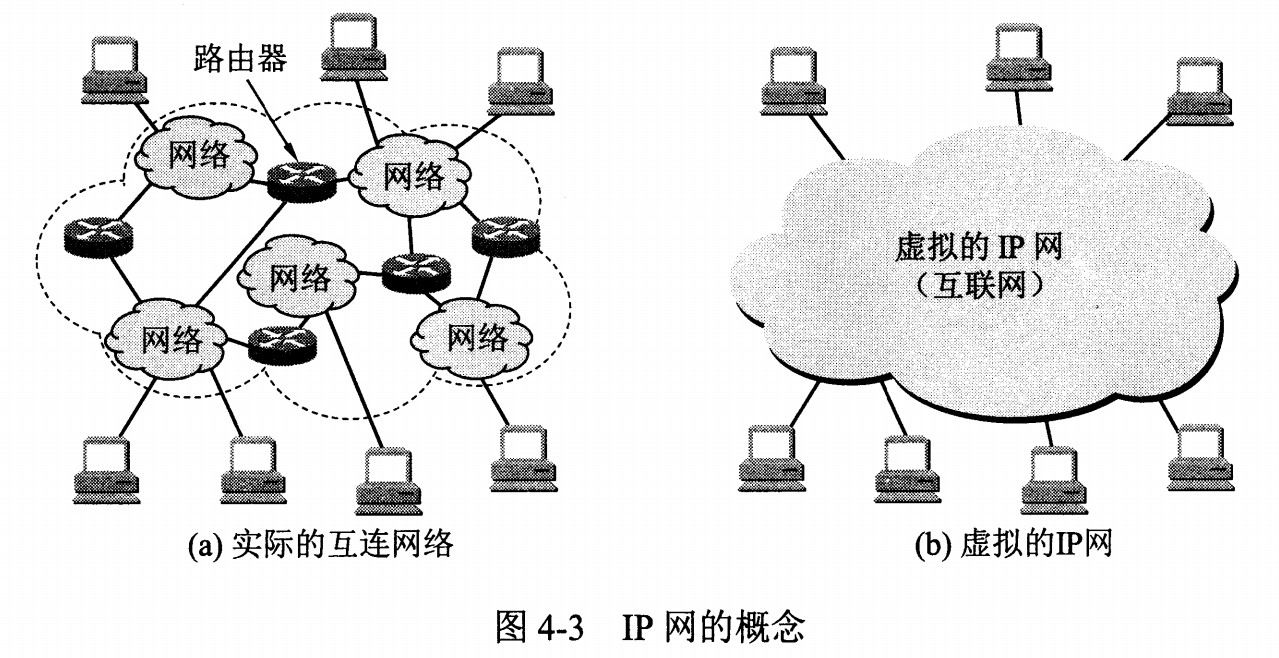
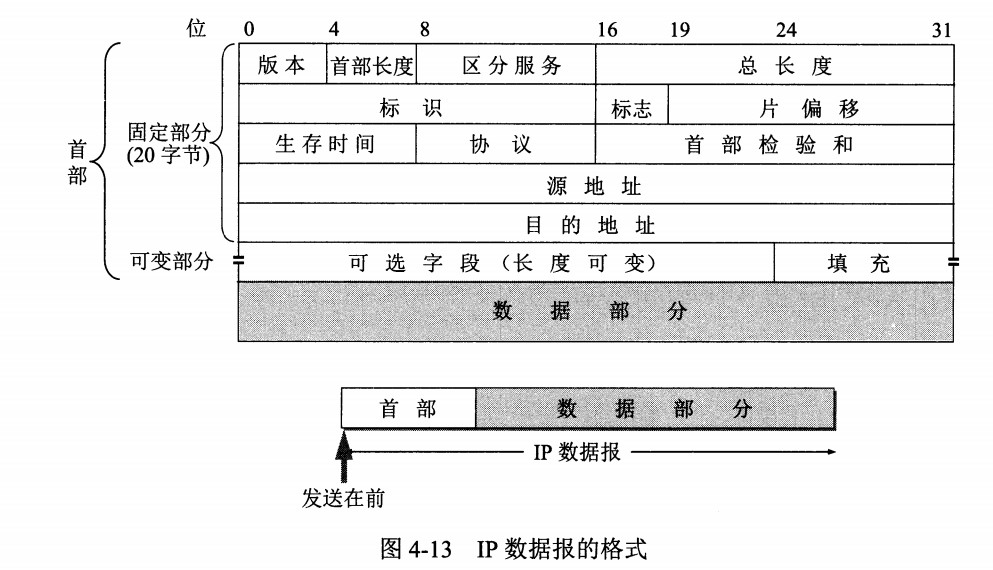
网络层实现主机之间的通信,而链路层实现具体每段链路之间的通信。因此在通信过程中,IP 数据报的源地址和目的地址始终不变,而 MAC 地址随着链路的改变而改变。
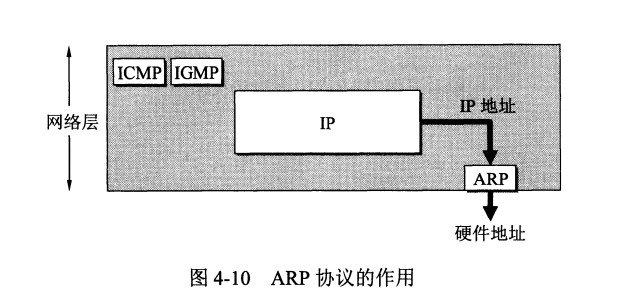
ARP 实现由 IP 地址得到 MAC 地址。
每个主机都有一个 ARP 高速缓存,里面有本局域网上的各主机和路由器的 IP 地址到 MAC 地址的映射表。
如果主机 A 知道主机 B 的 IP 地址,但是 ARP 高速缓存中没有该 IP 地址到 MAC 地址的映射,此时主机 A 通过广播的方式发送 ARP 请求分组,主机 B 收到该请求后会发送 ARP 响应分组给主机 A 告知其 MAC 地址,随后主机 A 向其高速缓存中写入主机 B 的 IP 地址到 MAC 地址的映射。
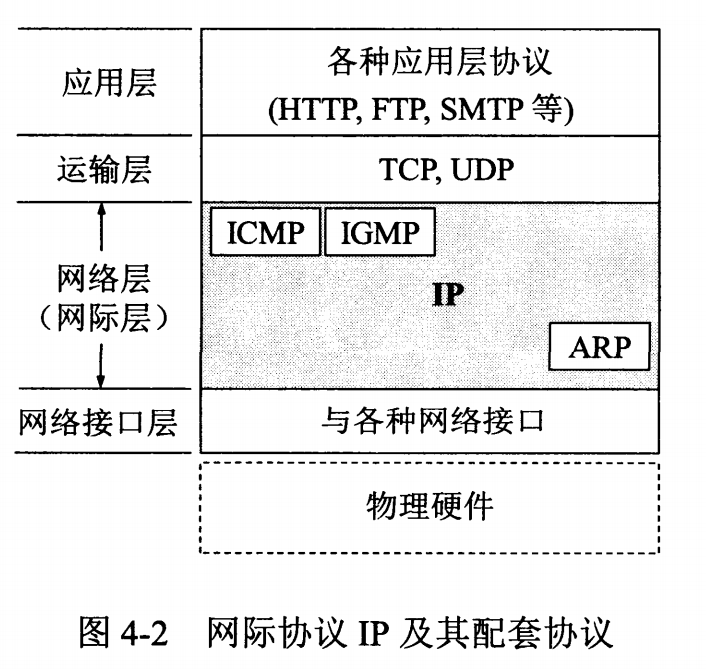
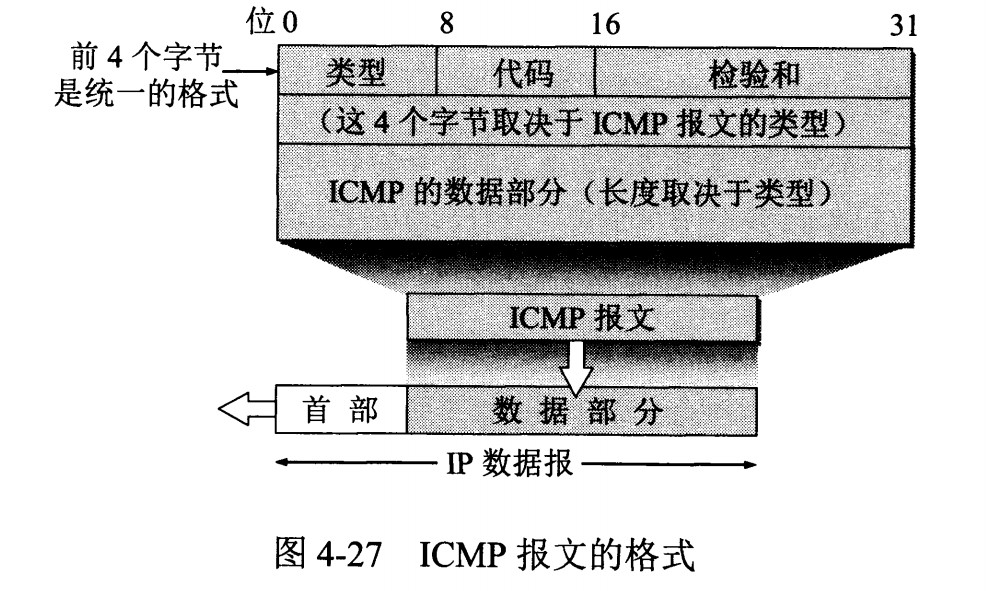
网际控制报文协议 ICMP
ICMP 是为了更有效地转发 IP 数据报和提高交付成功的机会。它封装在 IP 数据报中,但是不属于高层协议。
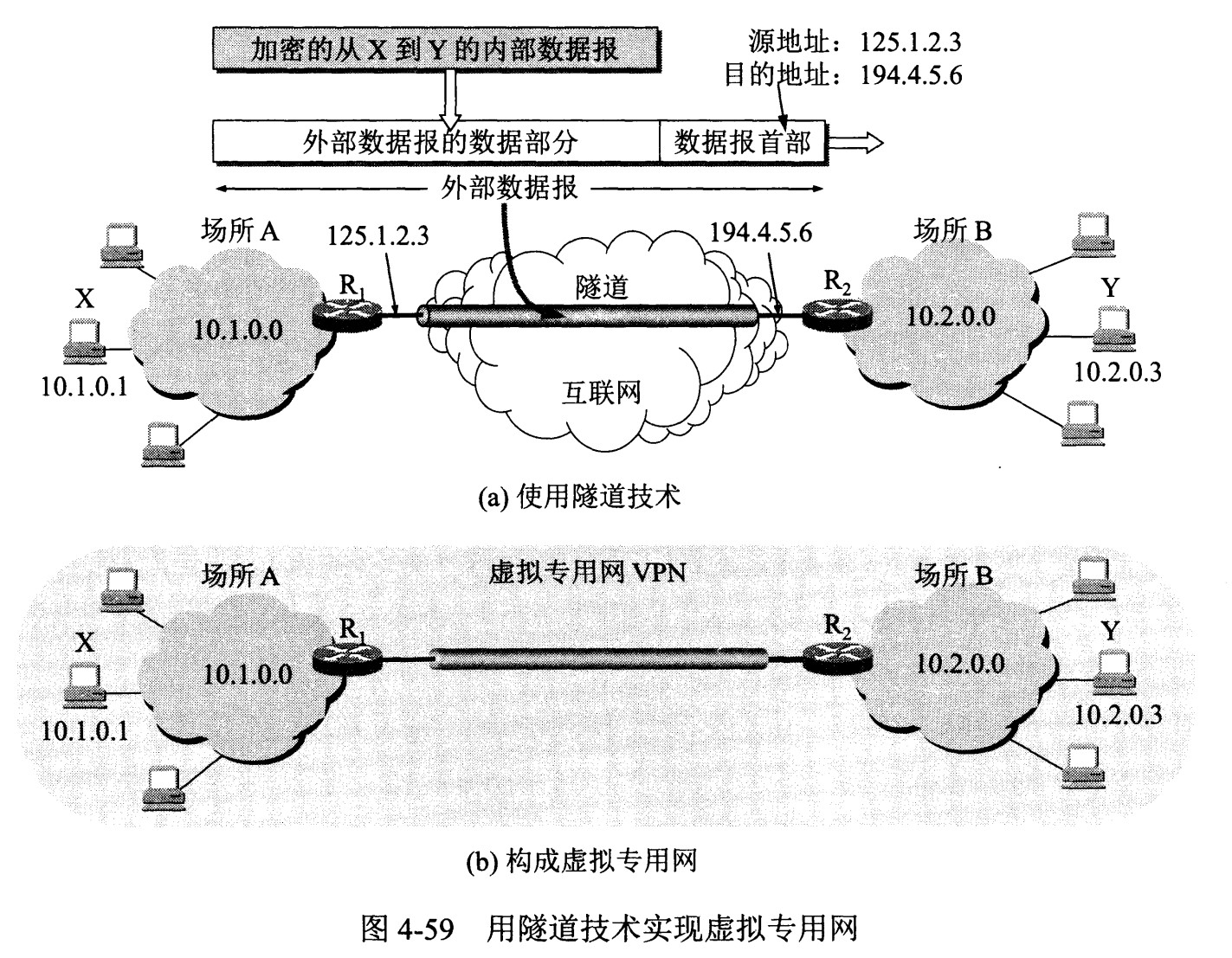
下图中,场所 A 和 B 的通信经过互联网,如果场所 A 的主机 X 要和另一个场所 B 的主机 Y 通信,IP 数据报的源地址是 10.1.0.1,目的地址是 10.2.0.3。数据报先发送到与互联网相连的路由器 R1,R1 对内部数据进行加密,然后重新加上数据报的首部,源地址是路由器 R1 的全球地址 125.1.2.3,目的地址是路由器 R2 的全球地址 194.4.5.6。路由器 R2 收到数据报后将数据部分进行解密,恢复原来的数据报,此时目的地址为 10.2.0.3,就交付给 Y。
网络地址转换 NAT
专用网内部的主机使用本地 IP 地址又想和互联网上的主机通信时,可以使用 NAT 来将本地 IP 转换为全球 IP。
在以前,NAT 将本地 IP 和全球 IP 一一对应,这种方式下拥有 n 个全球 IP 地址的专用网内最多只可以同时有 n 台主机接入互联网。为了更有效地利用全球 IP 地址,现在常用的 NAT 转换表把运输层的端口号也用上了,使得多个专用网内部的主机共用一个全球 IP 地址。使用端口号的 NAT 也叫做网络地址与端口转换 NAPT。
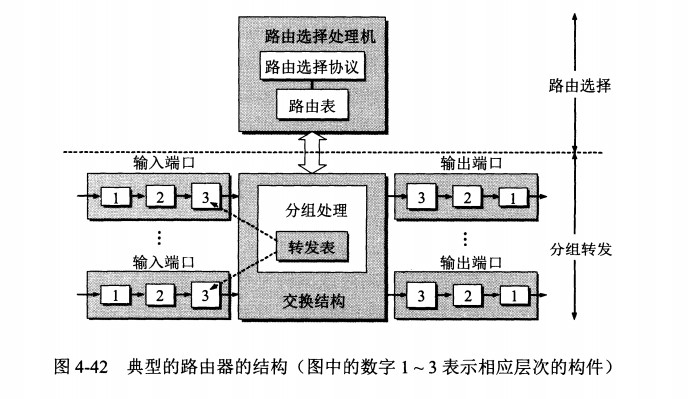
路由器的结构
路由器从功能上可以划分为:路由选择和分组转发。
分组转发结构由三个部分组成:交换结构、一组输入端口和一组输出端口。
路由器分组转发流程
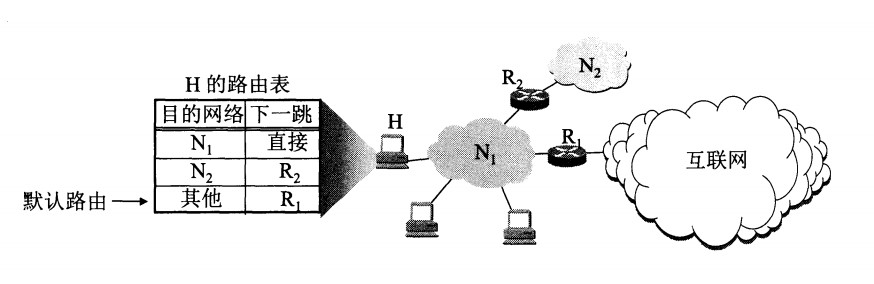
从数据报的首部提取目的主机的 IP 地址 D,得到目的网络地址 N。
若 N 就是与此路由器直接相连的某个网络地址,则进行直接交付;
若路由表中有目的地址为 D 的特定主机路由,则把数据报传送给表中所指明的下一跳路由器;
若路由表中有到达网络 N 的路由,则把数据报传送给路由表中所指明的下一跳路由器;
若路由表中有一个默认路由,则把数据报传送给路由表中所指明的默认路由器;
报告转发分组出错。
路由选择协议
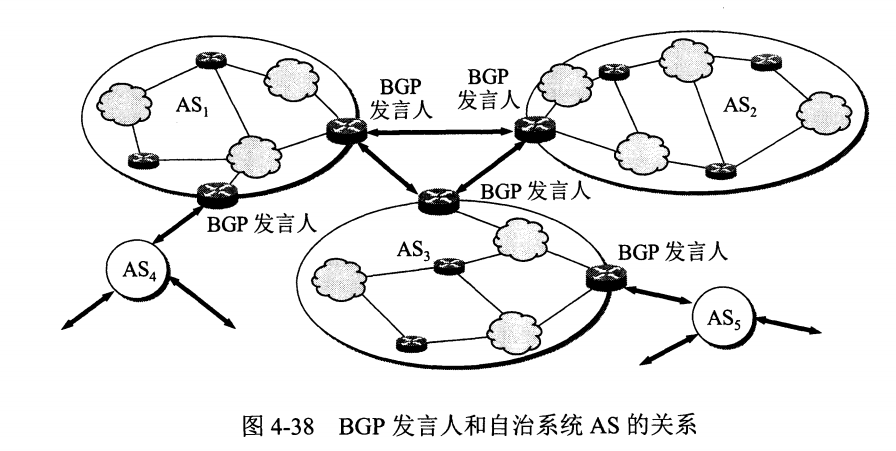
路由选择协议都是自适应的,能随着网络通信量和拓扑结构的变化而自适应地进行调整。
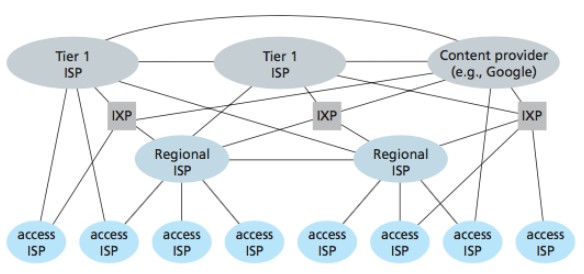
互联网可以划分为许多较小的自治系统 AS,一个 AS 可以使用一种和别的 AS 不同的路由选择协议。
该报文段则被放入在一个具有广播 IP 目的地址(255.255.255.255) 和源 IP 地址(0.0.0.0)的 IP 数据报中。
该数据报则被放置在 MAC 帧中,该帧具有目的地址 FF:FF:FF:FF:FF:FF,将广播到与交换机连接的所有设备。
连接在交换机的 DHCP 服务器收到广播帧之后,不断地向上分解得到 IP 数据报、UDP 报文段、DHCP 请求报文,之后生成 DHCP ACK 报文,该报文包含以下信息:IP 地址、DNS 服务器的 IP 地址、默认网关路由器的 IP 地址和子网掩码。该报文被放入 UDP 报文段中,UDP 报文段有被放入 IP 数据报中,最后放入 MAC 帧中。
该帧的目的地址是请求主机的 MAC 地址,因为交换机具有自学习能力,之前主机发送了广播帧之后就记录了 MAC 地址到其转发接口的交换表项,因此现在交换机就可以直接知道应该向哪个接口发送该帧。
主机收到该帧后,不断分解得到 DHCP 报文。之后就配置它的 IP 地址、子网掩码和 DNS 服务器的 IP 地址,并在其 IP 转发表中安装默认网关。
2. ARP 解析 MAC 地址
主机通过浏览器生成一个 TCP 套接字,套接字向 HTTP 服务器发送 HTTP 请求。为了生成该套接字,主机需要知道网站的域名对应的 IP 地址。
主机生成一个 DNS 查询报文,该报文具有 53 号端口,因为 DNS 服务器的端口号是 53。
该 DNS 查询报文被放入目的地址为 DNS 服务器 IP 地址的 IP 数据报中。
该 IP 数据报被放入一个以太网帧中,该帧将发送到网关路由器。
DHCP 过程只知道网关路由器的 IP 地址,为了获取网关路由器的 MAC 地址,需要使用 ARP 协议。
主机生成一个包含目的地址为网关路由器 IP 地址的 ARP 查询报文,将该 ARP 查询报文放入一个具有广播目的地址(FF:FF:FF:FF:FF:FF)的以太网帧中,并向交换机发送该以太网帧,交换机将该帧转发给所有的连接设备,包括网关路由器。
网关路由器接收到该帧后,不断向上分解得到 ARP 报文,发现其中的 IP 地址与其接口的 IP 地址匹配,因此就发送一个 ARP 回答报文,包含了它的 MAC 地址,发回给主机。
3. DNS 解析域名
知道了网关路由器的 MAC 地址之后,就可以继续 DNS 的解析过程了。
网关路由器接收到包含 DNS 查询报文的以太网帧后,抽取出 IP 数据报,并根据转发表决定该 IP 数据报应该转发的路由器。
因为路由器具有内部网关协议(RIP、OSPF)和外部网关协议(BGP)这两种路由选择协议,因此路由表中已经配置了网关路由器到达 DNS 服务器的路由表项。
到达 DNS 服务器之后,DNS 服务器抽取出 DNS 查询报文,并在 DNS 数据库中查找待解析的域名。
找到 DNS 记录之后,发送 DNS 回答报文,将该回答报文放入 UDP 报文段中,然后放入 IP 数据报中,通过路由器反向转发回网关路由器,并经过以太网交换机到达主机。
4. HTTP 请求页面
有了 HTTP 服务器的 IP 地址之后,主机就能够生成 TCP 套接字,该套接字将用于向 Web 服务器发送 HTTP GET 报文。
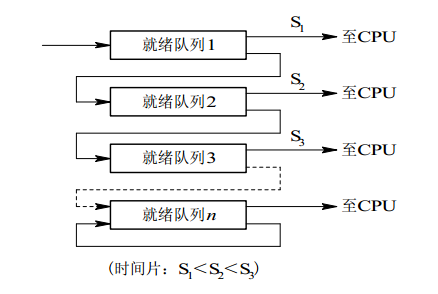
procedureinsert(item: integer); begin if count = N then wait(full); insert_item(item); count := count + 1; if count = 1then signal(empty); end;
functionremove: integer; begin if count = 0then wait(empty); remove = remove_item; count := count - 1; if count = N -1then signal(full); end; end monitor;
// 生产者客户端 procedureproducer begin whiletruedo begin item = produce_item; ProducerConsumer.insert(item); end end;
// 消费者客户端 procedureconsumer begin whiletruedo begin item = ProducerConsumer.remove; consume_item(item); end end;
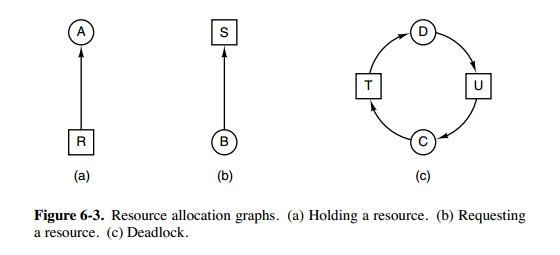
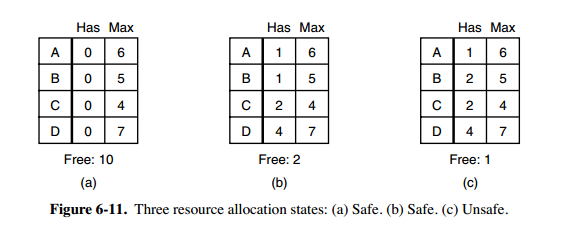
图 a 的第二列 Has 表示已拥有的资源数,第三列 Max 表示总共需要的资源数,Free 表示还有可以使用的资源数。从图 a 开始出发,先让 B 拥有所需的所有资源(图 b),运行结束后释放 B,此时 Free 变为 5(图 c);接着以同样的方式运行 C 和 A,使得所有进程都能成功运行,因此可以称图 a 所示的状态时安全的。
Progressive Web Apps (PWAs) are web applications that are regular web pages or websites, but can appear to the user like traditional applications or native mobile applications. The application type attempts to combine features offered by most modern browsers with the benefits of a mobile experience.
]]><blockquote>
<p>Progressive Web Apps (PWAs) are web applications that are regular web pages or websites, but can appear to the user like traLinux 基础知识https://blog.jugg.xyz/2018/04/03/repost/Linux/2018-04-03T07:53:30.000Z2024-06-04T10:08:06.251Z
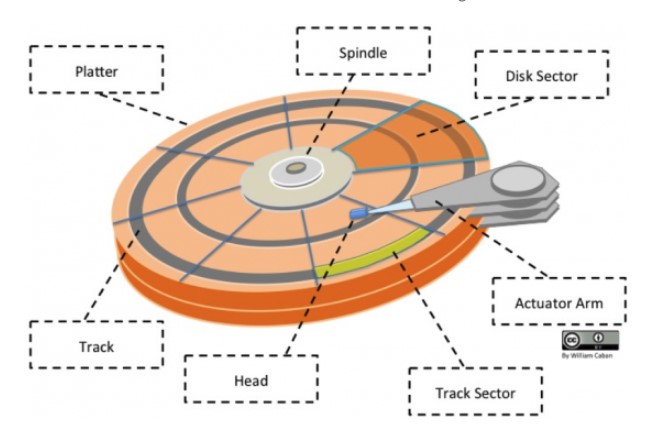
IDE(ATA)全称 Advanced Technology Attachment,接口速度最大为 133MB/s,因为并口线的抗干扰性太差,且排线占用空间较大,不利电脑内部散热,已逐渐被 SATA 所取代。
2. SATA
SATA 全称 Serial ATA,也就是使用串口的 ATA 接口,抗干扰性强,且对数据线的长度要求比 ATA 低很多,支持热插拔等功能。SATA-II 的接口速度为 300MiB/s,而新的 SATA-III 标准可达到 600MiB/s 的传输速度。SATA 的数据线也比 ATA 的细得多,有利于机箱内的空气流通,整理线材也比较方便。
3. SCSI
SCSI 全称是 Small Computer System Interface(小型机系统接口),经历多代的发展,从早期的 SCSI-II 到目前的 Ultra320 SCSI 以及 Fiber-Channel(光纤通道),接口型式也多种多样。SCSI 硬盘广为工作站级个人电脑以及服务器所使用,因此会使用较为先进的技术,如碟片转速 15000rpm 的高转速,且传输时 CPU 占用率较低,但是单价也比相同容量的 ATA 及 SATA 硬盘更加昂贵。
4. SAS
SAS(Serial Attached SCSI)是新一代的 SCSI 技术,和 SATA 硬盘相同,都是采取序列式技术以获得更高的传输速度,可达到 6Gb/s。此外也透过缩小连接线改善系统内部空间等。
磁盘的文件名
Linux 中每个硬件都被当做一个文件,包括磁盘。磁盘以磁盘接口类型进行命名,常见磁盘的文件名如下:
文件名不是存储在一个文件的内容中,而是存储在一个文件所在的目录中。因此,拥有文件的 w 权限并不能对文件名进行修改。
目录存储文件列表,一个目录的权限也就是对其文件列表的权限。因此,目录的 r 权限表示可以读取文件列表;w 权限表示可以修改文件列表,具体来说,就是添加删除文件,对文件名进行修改;x 权限可以让该目录成为工作目录,x 权限是 r 和 w 权限的基础,如果不能使一个目录成为工作目录,也就没办法读取文件列表以及对文件列表进行修改了。
链接
1 2 3
# ln [-sf] source_filename dist_filename -s :默认是 hard link,加 -s 为 symbolic link -f :如果目标文件存在时,先删除目标文件
$ cut -d :分隔符 -f :经过 -d 分隔后,使用 -f n 取出第 n 个区间 -c :以字符为单位取出区间
示例 1:last 显示登入者的信息,取出用户名。
1 2 3 4 5 6
$ last root pts/1 192.168.201.101 Sat Feb 7 12:35 still logged in root pts/1 192.168.201.101 Fri Feb 6 12:13 - 18:46 (06:33) root pts/1 192.168.201.254 Thu Feb 5 22:37 - 23:53 (01:16)
示例:把含有 the 字符串的行提取出来(注意默认会有 –color=auto 选项,因此以下内容在 Linux 中有颜色显示 the 字符串)
1 2 3 4 5 6
$ grep -n 'the' regular_express.txt 8:I can't finish the test. 12:the symbol '*' is represented as start. 15:You are the best is mean you are the no. 1. 16:The world Happy is the same with "glad". 18:google is the best tools for search keyword
近年来,Stack Exchange community 社区已经成为回答技术及其他问题的主要渠道,尤其是那些开放源码的项目。
因为 Google 索引是即时的,在看 Stack Exchange 之前先在 Google 搜索。有很高的机率某人已经问了一个类似的问题,而且 Stack Exchange 网站们往往会是搜索结果中最前面几个。如果你在 Google 上没有找到任何答案,你再到特定相关主题的网站去找。用标签(Tag)搜索能让你更缩小你的搜索结果。
最有效描述程序问题的方法是提供最精简的Bug展示测试示例(bug-demonstrating test case)。什么是最精简的测试示例? 那是问题的缩影;一小个程序片段能刚好展示出程序的异常行为,而不包含其他令人分散注意力的内容。怎么制作最精简的测试示例?如果你知道哪一行或哪一段代码会造成异常的行为,复制下来并加入足够重现这个状况的代码(例如,足以让这段代码能被编译/直译/被应用程序处理)。如果你无法将问题缩减到一个特定区块,就复制一份代码并移除不影响产生问题行为的部分。总之,测试示例越小越好(查看话不在多而在精一节)。
当然,这风险很大,因为黑客们兴奋的点多半与你的不同。譬如从 NASA 国际空间站(International Space Station)发这样的标题没有问题,但用自我感觉良好的慈善行为或政治原因发肯定不行。事实上,张贴诸如紧急:帮我救救这个毛绒绒的小海豹!肯定让你被黑客忽略或惹恼他们,即使他们认为毛绒绒的小海豹很重要。
我在 S2464 主机板上试过了 X 、 Y 和 Z ,但没什么作用,我又试了 A 、 B 和 C 。请注意当我尝试 C 时的奇怪现象。显然 florbish 正在 grommicking,但结果出人意料。通常在 Athlon MP 主机板上引起 grommicking 的原因是什么?有谁知道接下来我该做些什么测试才能找出问题?
这个家伙,从另一个角度来看,值得去回答他。他表现出了解决问题的能力,而不是坐等天上掉答案。
在最后一个问题中,注意告诉我答案和给我启示,指出我还应该做什么诊断工作之间微妙而又重要的区别。
事实上,后一个问题源自于 2001 年 8 月在 Linux 内核邮件列表(lkml)上的一个真实的提问。我(Eric)就是那个提出问题的人。我在 Tyan S2464 主板上观察到了这种无法解释的锁定现象,列表成员们提供了解决这一问题的重要信息。
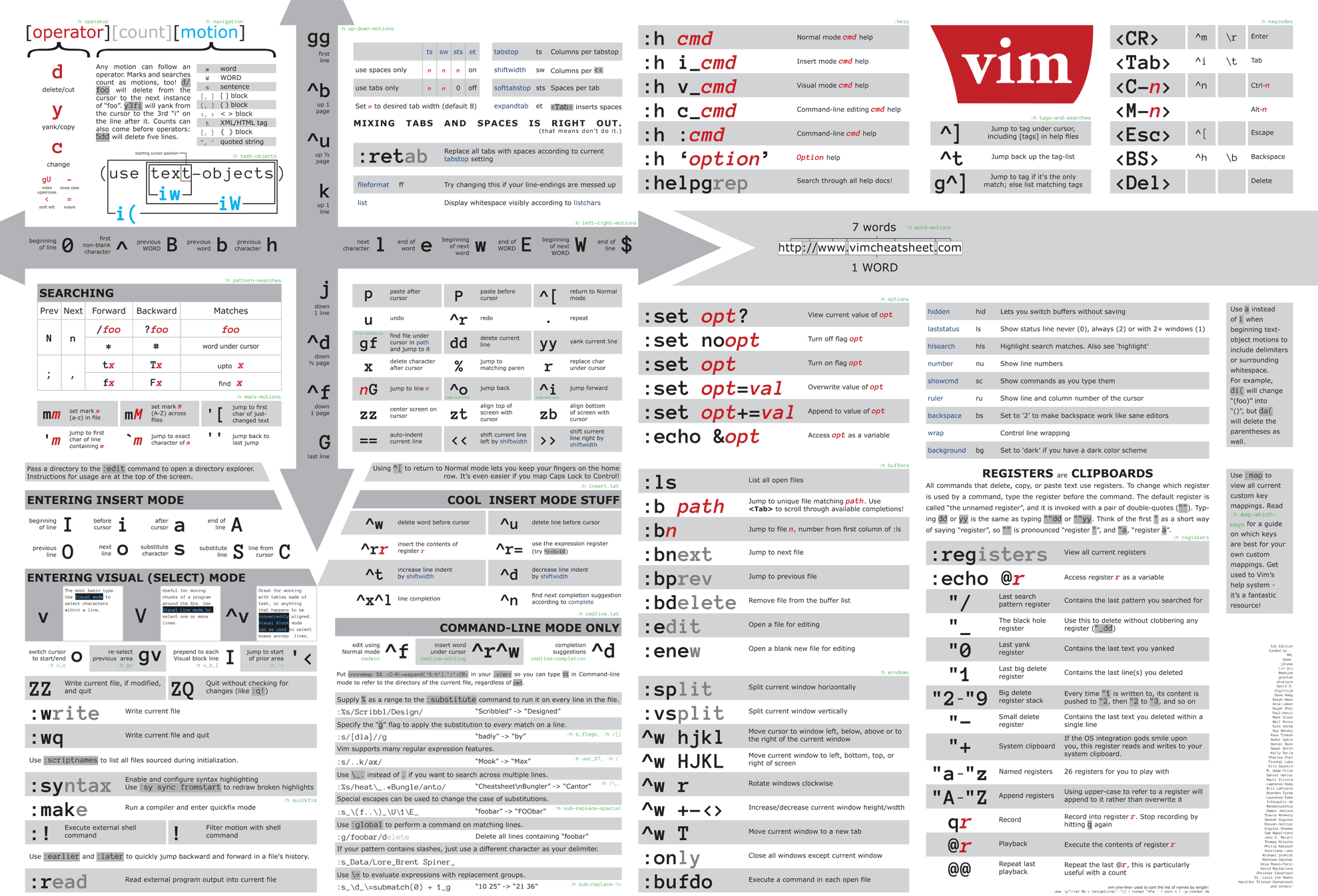
如果你能看见 Vim 老司机操作,你会发现他们使用 Vim 脚本语言就如同钢琴师弹钢琴一样。复杂的操作只需要几个按键就能完成。他们甚至不用刻意去想,因为这已经成为肌肉记忆了。这减少认识负荷并帮助人们专注于实际任务。
入门
Vim 自带一个交互式的教程,内含你需要了解的最基础的信息,你可以通过终端运行以下命令打开教程:
$ vimtutor
不要因为这个看上去很无聊而跳过,按照此教程多练习。你以前用的 IDE 或者其他编辑器很少是有“模式”概念的,因此一开始你会很难适应模式切换。但是你 Vim 使用的越多,肌肉记忆 将越容易形成。
Vim 基于一个 vi 克隆,叫做 Stevie,支持两种运行模式:”compatible” 和 “nocompatible”。在兼容模式下运行 Vim 意味着使用 vi 的默认设置,而不是 Vim 的默认设置。除非你新建一个用户的 vimrc 或者使用 vim -N 命令启动 Vim,否则就是在兼容模式下运行 Vim!请大家不要在兼容模式下运行 Vim。
第一行告诉你这个二进制文件的编译时间和版本号,比如:7.4。接下来的一行呈现 Included patches: 1-1051,这是补丁版本包。因此你 Vim 确切的版本号是 7.4.1051。
另一行显示着一些像 Tiny version without GUI 或者 Huge version with GUI 的信息。很显然这些信息告诉你当前的 Vim 是否支持 GUI,例如:从终端中运行 gvim 或者从终端模拟器中的 Vim 内运行 :gui 命令。另一个重要的信息是 Tiny 和 Huge。Vim 的特性集区分被叫做 tiny,small,normal,big and huge,所有的都实现不同的功能子集。
如果你的输出情况并不是那样,并且你是从包管理器安装 Vim 的,确保你安装了 vim-x,vim-x11,vim-gtk,vim-gnome 这些包或者相似的,因为这些包通常都是 huge 模式编译的。
你也可以运行下面这段代码来测试 Vim 版本以及功能支持:
1 2 3 4
" Do something if running at least Vim 7.4.42 with +profile enabled. if (v:version > 704 || v:version == 704 && has('patch42')) && has('profile') " do stuff endif
有时,Vim 会在命令前自动添加范围。举个例子,如果你先通过 V 命令进入行选取模式,选中一些行后按下 : 进入命令模式,这时候你会发现 Vim 自动添加了 '<,'> 范围。这表示,接下来的命令会使用之前选取的行号作为范围。但如果后续命令不支持范围,Vim 就会报错。为了避免这样的情况发生,有些人会设置这样的按键映射::vnoremap foo :<c-u>command,组合键 Ctrl + u 可以清除当前命令行中的内容。
另一个例子是在普通模式中按下 !!,命令行中会出现 :.!。如果这时你如果输入一个外部命令,那么当前行的内容就会被这个外部命令的输出替换。你也可以通过命令 :?^$?+1,/^$/-1!ls 把当前段落的内容替换成外部命令 ls 的输出,原理是向前和向后各搜索一个空白行,删除这两个空白行之间的内容,并将外部命令 ls 的输出放到这两个空白行之间。
0 代表 viminfo 最后一次被写入的位置。实际使用中,就代表 Vim 进程最后一次结束的位置。1 代表 Vim 进程倒数第二次结束的位置,以此类推
如果想跳转到指定的标注,你可以先按下 ' / g' 或者 ` / g` 然后按下标注名。
如果你想定义当前文件中的标注,可以先按下 m 再按下标注名。比如,按下 mm 就可以把当前位置标注为 m。在这之后,如果你的光标切换到了文件的其他位置,只需要通过 'm 或者 `m即可回到刚才标注的行。区别在于,'m会跳转回被标记行的第一个非空字符,而`m会跳转回被标记行的被标记列。根据 viminfo 的设置,你可以在退出 Vim 的时候保留小写字符标注。请参阅:h viminfo-' 来获取更多帮助。
如果你想定义全局的标注,可以先按下 m 再按下大写英文字符。比如,按下 mM 就可以把当前文件的当前位置标注为 M。在这之后,就算你切换到其他的缓冲区,依然可以通过 'M 或 `M 跳转回来。
针对不同的补全方案,Vim 为我们提供了不同的按键映射。这些映射都是在插入模式中通过 Ctrl + x 来触发:
映射
类型
帮助文档
<c-x><c-l>
整行
:h i^x^l
<c-x><c-n>
当前缓冲区中的关键字
:h i^x^n
<c-x><c-k>
字典(请参阅 :h 'dictionary')中的关键字
:h i^x^k
<c-x><c-t>
同义词字典(请参阅 :h 'thesaurus')中的关键字
:h i^x^t
<c-x><c-i>
当前文件以及包含的文件中的关键字
:h i^x^i
<c-x><c-]>
标签
:h i^x^]
<c-x><c-f>
文件名
:h i^x^f
<c-x><c-d>
定义或宏定义
:h i^x^d
<c-x><c-v>
Vim 命令
:h i^x^v
<c-x><c-u>
用户自定义补全(通过 'completefunc' 定义)
:h i^x^u
<c-x><c-o>
Omni Completion(通过 'omnifunc' 定义)
:h i^x^o
<c-x>s
拼写建议
:h i^Xs
尽管用户自定义补全与 Omni Completion 是不同的,但他们做的事情基本一致。共同点在于,他们都是一个监听当前光标位置的函数,返回值为一系列的补全建议。用户自定义补全是由用户定义的,基于用户的个人用途,因此你可以根据自己的喜好和需求随意定制。而 Omni Completion 是针对文件类型的补全,比如在 C 语言中补全一个结构体(struct)的成员(members),或者补全一个类的方法,因而它通常都是由文件类型插件设置和调用的。
撤销 u 与重做 Ctrl + r 操作是按分支遍历。对于上面的例子,现在我们有三行字符。这时候按 u 会回退到 “bar” 节点,如果再按一次 u 则会回退到 “foo” 节点。这时,如果我们按下 Ctrl + r 就会前进至 “bar” 节点,再按一次就回前进至 “quux” 节点。在这种方式下,我们无法访问到兄弟节点(即 “baz” 节点)。
" 如果文件夹不存在,则新建文件夹 if !isdirectory($HOME.'/.vim/files') && exists('*mkdir') callmkdir($HOME.'/.vim/files') endif
" 备份文件 set backup set backupdir =$HOME/.vim/files/backup/ set backupext =-vimbackup set backupskip = " 交换文件 set directory =$HOME/.vim/files/swap// set updatecount =100 " 撤销文件 setundofile set undodir =$HOME/.vim/files/undo/ " viminfo 文件 set viminfo ='100,n$HOME/.vim/files/info/viminfo
注意:如果你在一个多用户系统中编辑某个文件时, Vim 提示你交换文件已经存在的话,可能是因为有其他的用户此时正在编辑这个文件。而如果将交换文件放到自己的 home 目录的话,这个功能就失效了。因此服务器非常不建议将这些文件修改到 HOME 目录,避免多人同时编辑一个文件,却没有任何警告。
编辑远程文件
Vim 自带的 netrw 插件支持对远程文件的编辑。实际上它将远程的文件通过 scp 复制到本地的临时文件中,再用那个文件打开一个缓冲区,然后在保存时把文件再复制回远程位置。
下面的命令在你本地的 VIM 配置与 SSH 远程服务器上管理员想让你使用的配置有冲突时尤其有用:
1
:e scp://bram@awesome.site.com/.vimrc
如果你已经设置了 ~/.ssh/config,SSH 会自动读取这里的配置:
Host awesome HostName awesome.site.com Port 1234 User bram
ifempty($TMUX) let &t_SI = "\<Esc>]50;CursorShape=1\x7" let &t_EI = "\<Esc>]50;CursorShape=0\x7" let &t_SR = "\<Esc>]50;CursorShape=2\x7" else let &t_SI = "\<Esc>Ptmux;\<Esc>\<Esc>]50;CursorShape=1\x7\<Esc>\\" let &t_EI = "\<Esc>Ptmux;\<Esc>\<Esc>]50;CursorShape=0\x7\<Esc>\\" let &t_SR = "\<Esc>Ptmux;\<Esc>\<Esc>]50;CursorShape=2\x7\<Esc>\\" endif
原理很简单,就是让 Vim 在进入和离开插入模式的时候,输出一些序列,请参考 escape sequence。Vim 与终端之间的中间层,比如 tmux 会处理并执行上面的代码。
但上面这个还是有一个缺点的。终端环境的内部原理不尽相同,对于序列的处理方式也稍有不同。因此,上面的代码可能无法在你的环境中运行。甚至,你的运行环境也有可能不支持其他光标形状,请参阅你的 Vim 运行环境的文档。
:au BufWritePost " signify BufWritePost " * call sy#start() :breakadd func *start :w " Breakpoint in "sy#start" line 1 " Entering Debug mode. Type "cont" to continue. " function sy#start " line 1: if g:signify_locked >s " function sy#start " line 3: endif > " function sy#start " line 5: let sy_path = resolve(expand('%:p')) >q :breakdel *



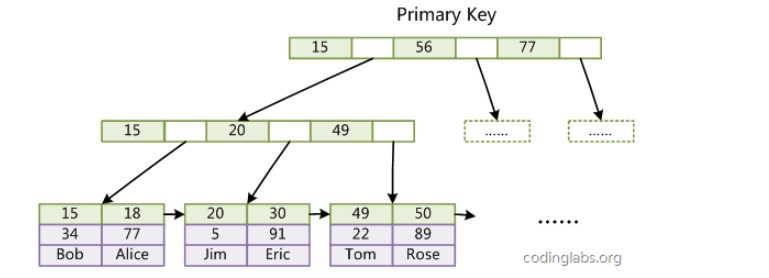
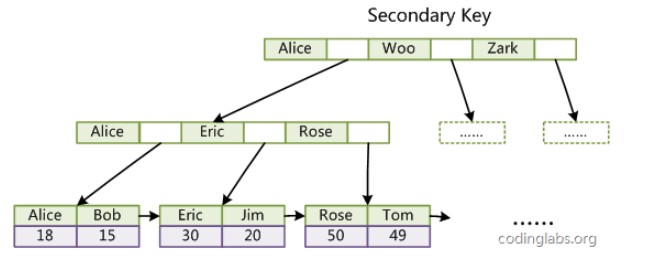


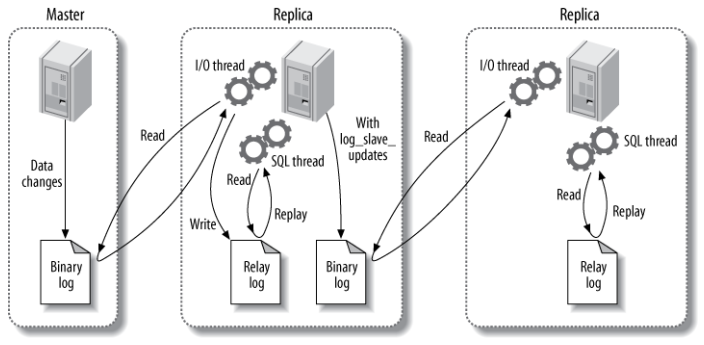
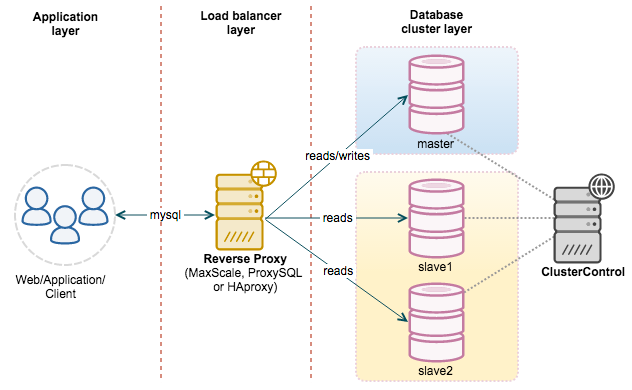













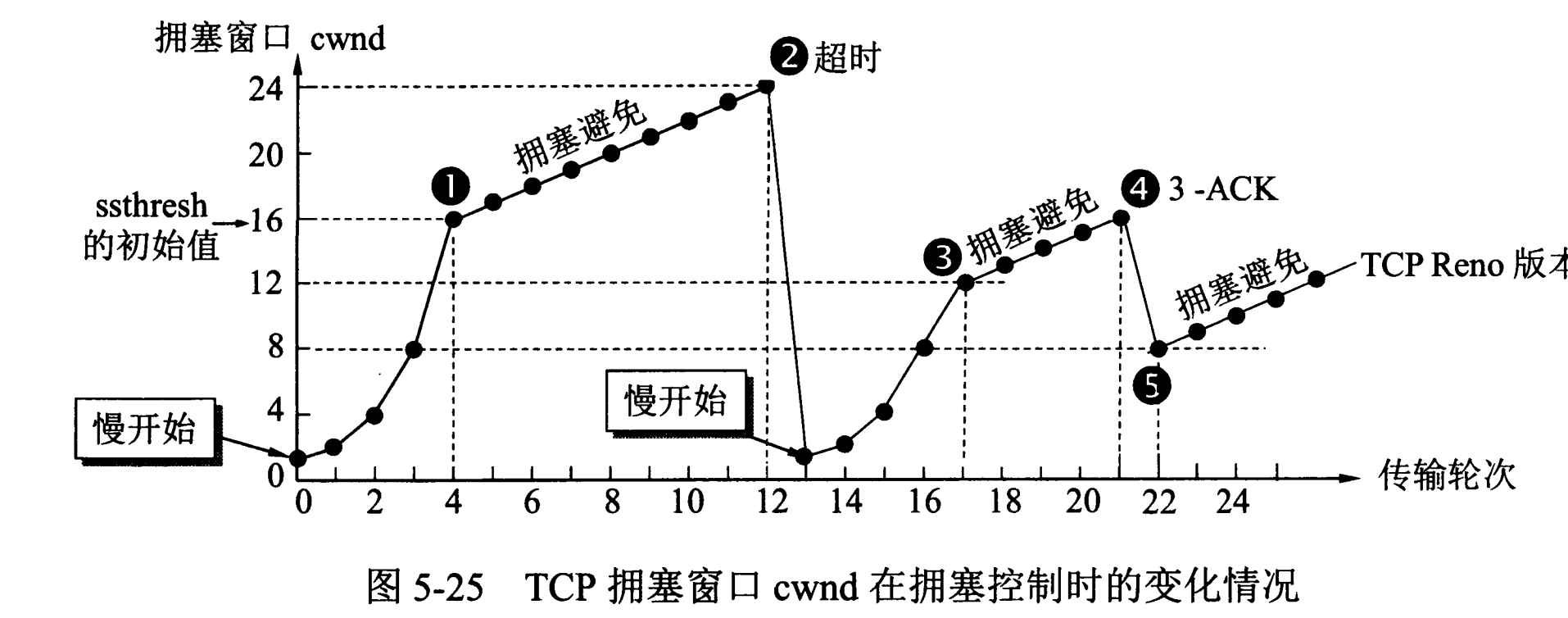





























{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}